Introduction: (Decision Trees and Random Forests
In the ever-evolving world of artificial intelligence and data-driven decision-making, two robust algorithms stand out for their simplicity and effectiveness: Decision Trees and random forests. The interpretability and the accuracy properties make these machine learning techniques widely used for classification and or regression tasks. In this blog, we’re going to see how these models work and share some insights from one implementation with the famous Iris dataset
Decision Trees and Random Forests : Predictive Power Foundation
Explanation:
The power of predicting a result is what the foundation of predictive power is.
Which one should deals first from Decision Trees and Random Forests ?
Decision Trees
Decision Tree is a treelike structure where every internal node denotes a test on an attribute. Each branch represents an outcome of the test, and each leaf node holds a class label. Interpreting decision trees is straightforward and powerful, and this ability makes decision trees useful in domains ranging from finance to healthcare to retail.
Key Steps in Implementing a Decision Trees and Random Forests
- Data Preparation: Preprocessing and loading dataset and separate input feature (X) and target variable(Y).
- Training: We fit a Decision Tree classifier on the training data.
- Visualization: Easy interpretability of the process by generating a graphical representation.
- Evaluation: Assess model performance on unseen test data using metrics such as accuracy.
For our experiment, we trained a Decision Tree on the Iris dataset. Which included data about different species of Iris flowers. We were able to predict the class on unseen samples accurately using Python’s sklearn library and visualize the decision tree. Results showed that models make effective split decisions to classify flower species.
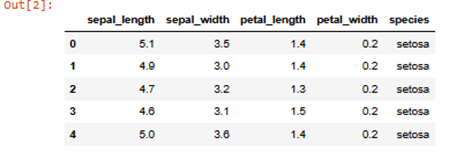
Import libraries and iris data set
Code:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df=sns.load_dataset("iris")
#To show data set print
df.head() #this show first five rows
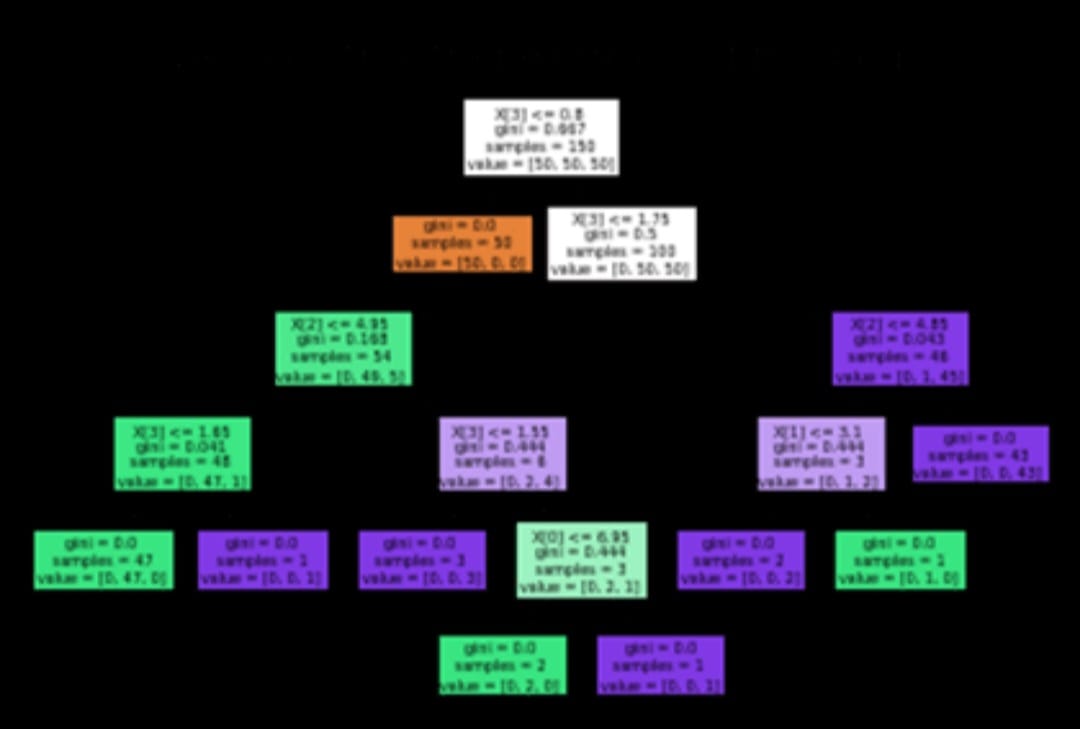
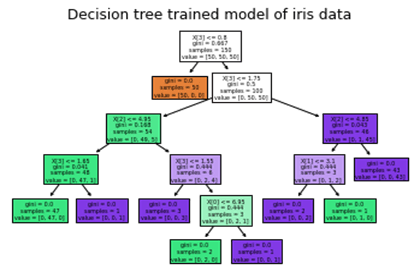
Code for decision tree map:
DecisionTreeClassifier is from sklearn.tree.
plot_tree from sklearn.tree.
model=DecisionTreeClassifier().fit(x,y)
plot_tree(model,filled=True)
The trained model of iris data is plotted as a decision tree.
Code Example for Calculating Accuracy:
Now it’s time to check the accuracy of model Import useful libraries of decision tree model
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
Splitting data into training and testing sets
Usually we split data into two parts one for training set and other for test set
Code
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42Training the Decision Tree
dt_model = DecisionTreeClassifier()
dt_model.fit(x_train, y_train)
Making predictions
dt_predictions = dt_model.predict(x_test)Evaluating the model
dt_accuracy = accuracy_score(y_test, dt_predictions)
print("Accuracy of the Decision Tree model:", dt_accuracy)
Output : 1.00
This 100% show model is highly accurate, but we don’t want hundreds accuracy. But while practicing on given data if we use very high quality data then it can happen.
Random Forests: The Ensemble Advantage:
Random Forest is an ensemble learning technique that trains several decision trees and forms their predictions to increase the accuracy and robustness of prediction. As an example, Random Forests typically outperform individual decision trees by reducing overfitting, and by using randomness to select features.
Implementation Highlights:
- Ensemble Creation: They train multiple decision trees on subsets of data.
- Majority Voting: Once all tree predictions are combined to obtain the final output (for classification).
- Performance Evaluation: Validation of the ensemble’s effectiveness is done by measuring accuracy.
To further prove our point, we tried Random Forests on the same dataset and the accuracy was so much better than the standalone Decision Tree model. With 100 estimators, our predictions were robust and consistent.
Code Example for Calculating Accuracy:
Some built in libraries that are essentially required to perform random forest model task must be imparted
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_splitSplitting data into training and testing sets:
Again, split data into two parts for train data and for test data
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)Training the Random Forest model:
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(x_train, y_train)Making predictions:
rf_predictions = rf_model.predict(x_test)Evaluating the model:
rf_accuracy = accuracy_score(y_test, rf_predictions)
print("Accuracy of the Random Forest model:", rf_accuracy)Output: 1.00. Show model is highly accurate though hundreds accuracy is not desirable. But it can happen when you work with very high quality data during practicing on given data .
Key Insights:
- Interpretability: Decision Trees clearly show how predictions are made.
- Accuracy and Stability:. Individual trees have higher accuracy and can take noisy data, but Random Forests have even higher accuracy and can deal with noisy data.
- Scalability: The two models are computationally efficient and scalable to large datasets.
Final Thoughts:
Decision Trees and Random Forests must know tools for any data scientist or machine learning practitioner. The simplicity, power and versatility of their combination make them suitable for a very broad range of applications, from disease diagnosis to product recommendation.
Experimenting these models is a great way to learn for those starting their journey in machine learning. We’ve found that these algorithms not only deliver high accuracy, but also enable you to understand your data in more depth, as you can see from our work with the Iris dataset.
Next, dive in and play a bit and see what you can do with Decision Trees and Random Forests in your projects. It’s endless, the possibilities!